情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]

情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]
クラウドの浸透により、買う(自分で設置)から、使う(利用する)に環境が変化しました。
基幹系、情報系に限らずICTインフラは、業務実行上欠かせない存在となりました。片時の不具合も許されません。
クラウドへの環境変化により、死活監視、リソース監視から、実際にアプリケーションが問題なく動作しているかどうかが重要となり、これを解決するために、“サービス監視(ストレス監視)”の時代へと変化します。
現状の問題点
現状の死活監視、リソース監視では、昨日のアプリケーションがストレスなく(遅延等)使えたかどうか証明ができません。
ICTインフラを構成するLAN群、WAN群、クラウド群といくつもの機器を通ります。どこかの機器のトラブルや、設定誤りでアプリケーションの利用を阻害します。ICTインフラを構成する機器が多くなり(Wifi、Router、Switch、FW、ロードバランサ、各種サーバ)、監視ができていない機器があります。
ICTインフラが複雑になり、ある時間帯において不具合が発生したり、使用環境(構成)が複雑化し、アプリケーションが使いにくい状況が発生することがあります。基本的な監視を行っていても不具合を発見できない場合があります。
例1:ping死活監視はokでも、ルーティングテーブルの更新ができない。
例2:プロセスは生きていても、アプリそのものの処理ができない。等
<5つの特長>
弊社では、この問題を解決するために、5つの特長ある保守サービスを行っています。
(1)アプリケーションレイヤーに近いレベルからの試験の有効性
縦 方向の End to End 試験
死活監視では分からない状況をよりアプリに近い試験を行うことによりお客さまの使い勝手を見える化します。
(2)クライアントからサーバまでの通し試験
横 方向の End to End 試験
利用する端末からサーバ(専用サーバ、クラウド)までには、スイッチ、ルータ、ネットワーク、ロードバランサ、Proxy、FW(ファイアーウォール)と色々な機器を通ります。その通しの試験を行うことが重要です。
(3)全機器の監視
できるだけ多く(できれば全ノード)の機器の試験を行うことが重要です。
(4)常時監視
悪い時にだけ試験を行うのではなく、常にITインフラの状況を把握しておく必要があります。
問題がない時の状況を把握し、少しでも状況が悪くなった場合に分かる仕組みが必要です。
(5)カスタマイズ試験
以下、それぞれについて説明します。
サーバのCPU能率、メモリ使用量、コネクション数、使用可能ディスク容量、死活監視では、お客さまの真のお困りが分かりません。
よりアプリに近い試験を行うことにより困り具合を見える化します。
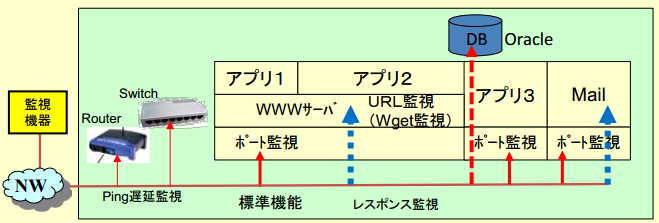
ping監視、ポート監視より上位の、サービス監視(URL監視、メール監視等)を行います。
かつ、応答のレスポンスを常時把握することにより、お客さまのストレス(体感)を見える化します。
例1:ping、25ポート、実際のメール、80ポート、実際のWEBアクセス 試験
下記のグラフを見て下さい。
① pingによる死活監視
② 25ポート:SMTP(メール)の試験
③ メールの実際の送受信試験
④ 80ポート:WWWの試験
⑤ Webサーバを実際に見に行く試験(Wget試験)
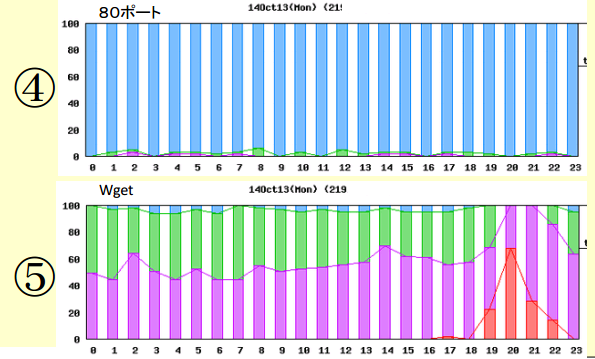
グラフはある日の1日のデータ(0時~23時)です。
グラフは100%表示で、青色は速い、緑は少し遅い、紫は遅い、赤はタイムアウトの割合を示します。
グラフから分かる通り、ping、ポート監視では、良好の結果(グラフの青は、レスポンスが良いことを示す)ですが、実際のアプリケーション利用では、遅延が発生していることが分かります。
①、②、④:ping、ポート監視 で問題なしの結果
③、⑤ :アプリケーションレイヤの試験 20時台に遅延、timeoutが発生しているのが分かります。
レスポンスの遅れの要因は、NW、機器、サーバ、その他各種あると考えられますが、エンドユーザとしては、ストレスが溜まることになります。
お客さまからの申告でレスポンスに影響があった日時のデータを元に、そのデータと同じような傾向ある場合は、お客さまの不満値を超えていることになります。
2014年10月13日(月)のある拠点のデータ

凡例 青:速い、緑:少し遅い、紫:遅い、赤:timeout
遅延から分かることのページを参照下さい。
参考:クラウド業者への質問のメール
【クラウド業者に聞いても分からない例】
<質問>
IP____のサーバで、
10月13日(月)19:50:47 ~ 20:30:07
で、接続できないアプリがあるログが発生しました。
_________のサイトで工事、トラブル情報を
少しみましたが、該当するような記事がありませんでした。
何か、上記の時間帯に、トラブル等発生していますでしょうか?
ご回答の程、よろしくお願いします。
<回答>
[〇〇 IPアドレス]が収容されるホストサーバについて確認いたし
ましたが、特に障害などが発生した記録はございませんでした。
お手数ではございますが、念のため今一度仮想サーバ内のログや
各種ソフトウェアなどの動作について、ご確認いただけますで
しょうか。
以上、何卒よろしくお願いいたします。
↑ページのトップへ
例2:クラウド利用の場合のレスポンスの違いの例
EECより、各クラウドセンタのサーバに、80ポートの試験、Wget試験(実際にWeb Pageにアクセス)を行います。
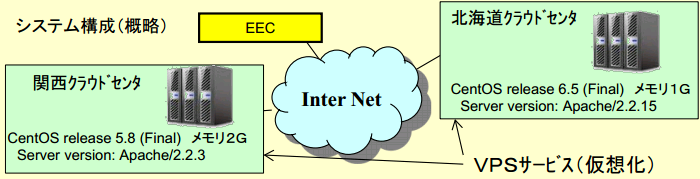
(1) 80ポート監視
ポート監視は、TCPの応答を見ているだけであり、関西CCと北海道CCのレスポンスの差は、平均で、関西CC:12.8ms、北海道CC:22.5ms
この試験結果は、距離の差として、妥当な値です。

(2) Wget(WWW)監視(よりアプリに近い)
関西CC:234ms、北海道CC:50ms という結果です。
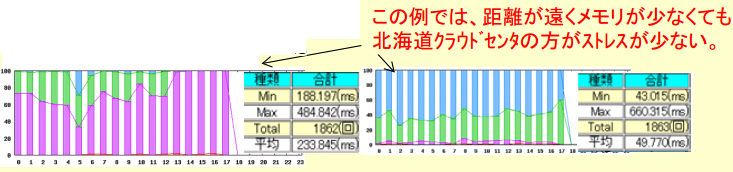
考察: メモリが多い、距離も近いクラウドセンタの方がレスポンスが良いと考えらますが、
実際は、距離も遠く、メモリも少ないバーチャルサーバの方が良いレスポンスでした。
*同じクラウドサービスでも、レスポンス(お客さまの不快感に影響)が大きく違うことが分かります。
より、アプリケーション(お客さま)に近いサービス監視(ストレス監視)が必要です。
通常のクラウドセンタでは、
① Ping監視
② Port監視
③ Syslog監視
④ リソース監視
等のサービスを提供されていますが、実際にお使いのお客さまのレスポンスはこれらの監視では分かりません。
レスポンスの劣化は、各種条件が集まった結果(「 遅延から分かること」にリンク)になりますので、できるだけ、アプリに近いレベルの試験が必要です。
よって、よりアプリに近い サービス監視 & レスポンス監視 を行うことにより、ITインフラの 実態を把握できます。
実態を把握することにより、
① 問題個所の絞り込みの迅速化
② エンドユーザからの申告前の発見
③ 兆候をみて、トラブルが悪化する前の発見
に貢献できます。
死活監視で異常がない場合でも、実際にお使いのお客さまからみて、使用に耐えられない“遅さ”がある場合があります。
混雑時はさらにその現象が顕著となり、エンドユーザ様の不満が高まります。
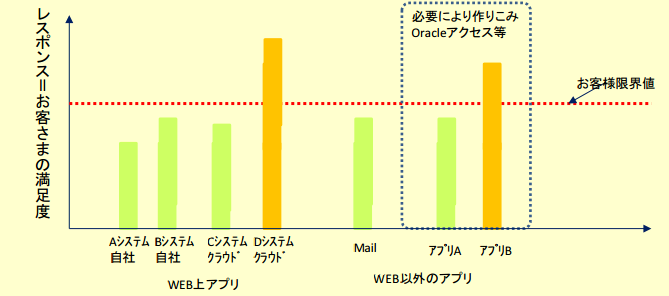
業務実行上とても大切な時間帯があります。
オーダの受付締切時間
月ぎめ処理時間
連休明けの業務開始時間 等
これらの時間帯にレスポンスが悪くなると、エンドユーザはリトライを繰り返し更にレスポンスが悪くなるという悪循環に陥ります。
ほとんどの時間で問題がなくても、上記のようなの時間帯で利用しずらい場合は、エンドユーザの満足度は落ちてしまいます。
弊社では、常時お客さまの利用されるアプリケーションのレスポンス値を常時、把握することにより、お客さまの不満の出る限界値を見える化します。
この限界値を超えないアクションを取り続けます。
今日のICTインフラは、色々な機器、NWを利用しておりますので、単体の試験が良好でも、クアイアント(端末)~サーバ(クラウド等含み)の通しの試験が良好かどうか分かりません。
FWを超えた試験を含む、横 方向の End to End 試験 が必要です。
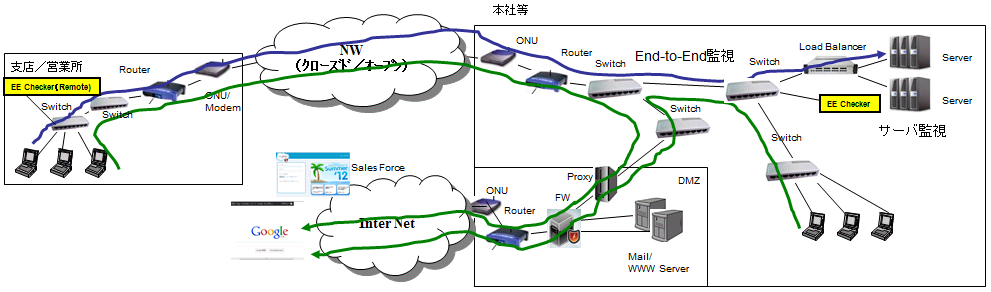
いつ、機器、NWにトラブルがあるか分かりません。できるだけ多くの機器の監視を行うことが有効です。
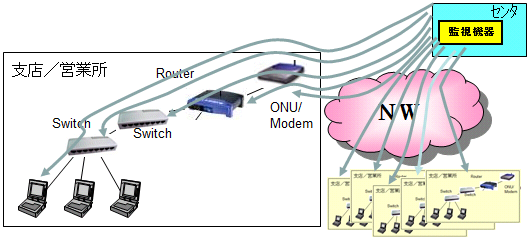
一般の保守会社のメニューでは、100ノードまでは、〇〇円、100ノードを超える、更に300ノードを超えると保守金額が跳ね上がる場合があります。
弊社では、監視をしないで急なトラブルの対応を行うより、できるだけ沢山のノードを監視し、緊急な対応を減らすことにより保守価格をリーズナブルなものにしています。
全てのトラブルを、エンドユーザ様の申告前に発見できれば、対応を余裕を持って行うことができます。
また、品質改善フローにより、トラブルになる前に対応することにより、保守価格を下げる努力をしております。
【発見例 その1】
6日毎に、1時間のサービス断が発生した事象の発見。
月データ 4日、10日、16日と定期的に故障していることが分かります。
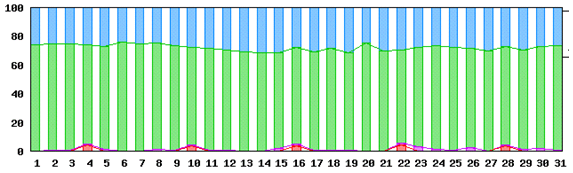
日データ 7、8時台にtimeoutが発生しているのが分かります。
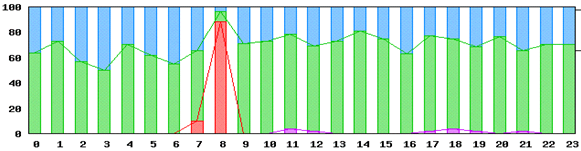
この例では、故障をしていない時にどんなに検証試験(ネットワークや、被疑機器の借用をしての確認試験)を行っても発見できません。
常時監視したログ情報を見ることにより、トラブルの発見に繋げることが可能です。
常時かつなるべく多くの機器を監視しておくことがポイントとなります。
【発見例 その2】
30秒程度のサービス断のある機器を発見した例。
統計処理で疑わしい拠点(ノード)については、試験間隔を短くします。最低1秒間隔の試験を実施できます。
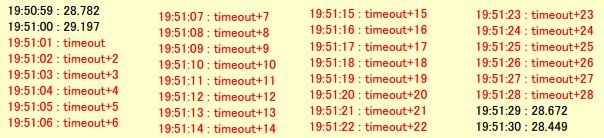
詳しくは
1分間隔の監視で発見できない事例 のページをご覧下さい。
ICTサービスが利用できない時にエンドユーザからの申告は辛辣です。
情報システム部門の方は、待ったなしで対応をする必要があります。
これを解決するには、問題解決のためい行った技術者の問題発見アルゴリズムをプログラミングした、”カスタマイズ試験” を実行することにより問題を解決することが可能です。
詳しくは、カスタマイズ試験 のページをご覧下さい。
