情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]

情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]
毎月、決まった日にデータセンターにあるサーバのアプリケーションが使えなくなりました。レスポンスが遅いので、Routerの電源をoff/onにすると復旧しました。
・回線の帯域を調べましたが、帯域をほとんど使用していなく、回線の圧迫はありませんでした。
・Routerのダウンを表すアラームも発生しておらず、電源をoffした時点で、回線ダウンアラームが発生しました。
原因が分からず、該当日になると、情報システム部員が待機し、電源のoff/onを実施する必要があり、その作業の間にアプリケーションが使えないと言う大きな問題でした。
【原因の要約】
あるサーバが、WindowsUPdateの後(月1回)のReboot後に大量の端末とのアクセスで接続エラーが発生し、このサーバが不要な信号パケットを多量に発生しました。Routerは、ダウンはしていないが、この大量処理のために、pingの応答もできない状態に陥り、監視装置はRouterの死活監視エラーとなり、ダウン状態とみなしてしまいました。
まず、異常時に大量にパケットを発生するサーバの特定を行い、そのサーバと接続しているパケットキャプチャーの分析を行いました。
その結果、サーバーが多くの機器と複数のプロセスを大量に発生していることが判明し、この処理を回避することにより問題を解決しました。
このページでは、原因究明に至った事項を詳細に記述します。
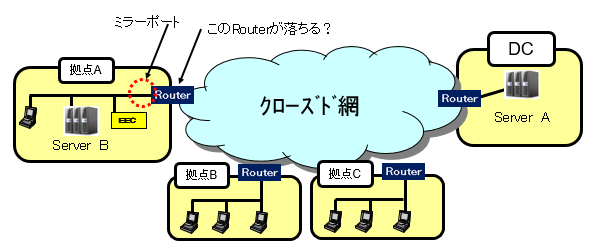
2.システム構成
使用できなくなる拠点のRouterのパケットをキャプチャーするために、Routerの通信が取れる場所にミラーポートを作成しました。
次の図が、今回のトラブル事象の全体構成です。
トラブルが生じた時のEECの通常監視のデータを示します。
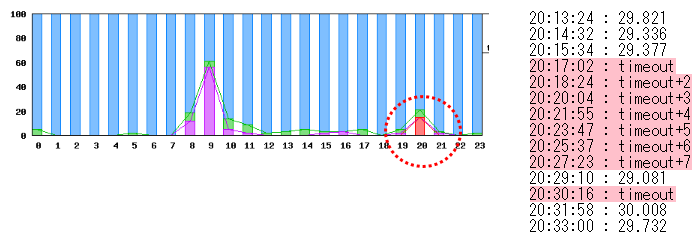
Routerの死活監視(ping) で timeout が発生しています。
現象からみると、Router 異常、回線異常と考えがちです。
3.パケットキャプチャー取得の工夫
パケットキャプチャーは、EEC(End to End Checker)のパケットキャプチャー機能を利用しました。
該当拠点に設置したEECに遠隔でパケットキャプチャーの起動を行いました。
また、「突発トラヒック見える化」機能を利用して、EECの監視対象拠点をダウンアラーム情報を元にパケットキャプチャーを実施し、自動的にパケットキャプチャーをすることで原因究明に役立ちました。
参考:パケットキャプチャー
突発トラヒック見える化
4.新たに発見されたサーバの通信
次に示しますのは、トラブル中のパケット通信の上位10のIPアドレスです。
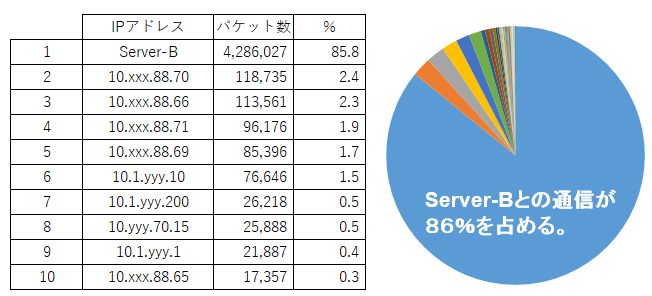
拠点Aの端末において、DC(Data Center)にあるServer-Aとの通信が遅いことが問題の起点でしたが、新たにServer-Bの通信が影響することが分かりました。
Server-Bがどの拠点の機器と通信を行っているか調べたところ、そのほとんどが、拠点B,C,D, .... との通信であることが分かりました。
次に示しますのは、
①パケットキャプチャーの全データ、②Server-Bの通信、③全データのTCPエラー、④Server-BのTCPエラー
のパケット数を示したWireSharkのグラフです。
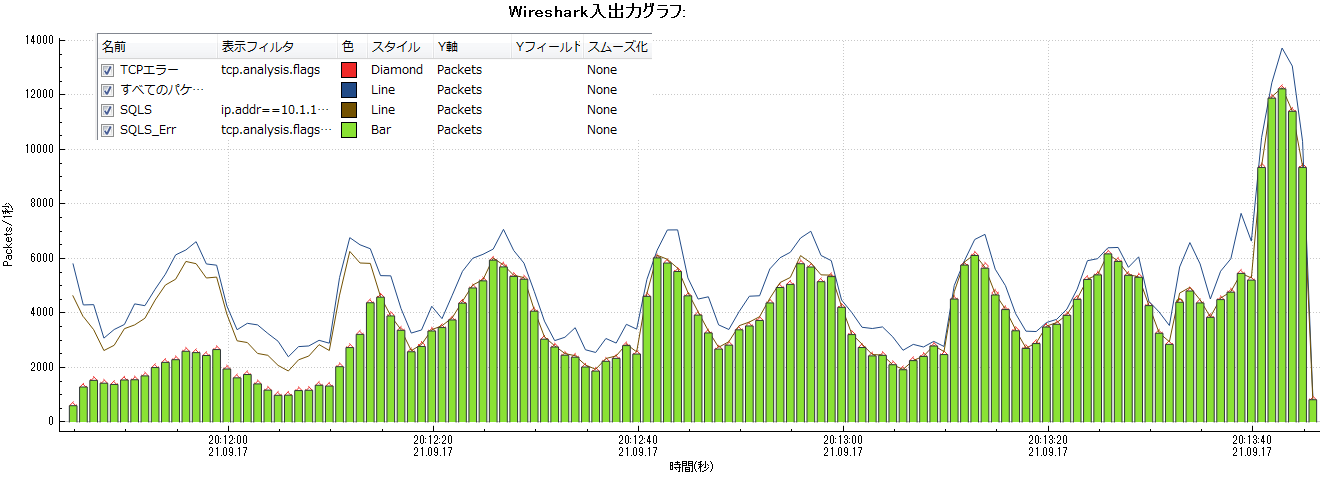
Server-Bの通信のほとんどが、TCPエラーの通信であることが分かります。
エラーパケットは情報量がほとんどないため、使用帯域はごく僅かになっています。帯域には余裕があるのにServer-Bの通信のため他の通信ができない状態に陥りました。
ここで注意が必要なのは、Routerとしては、ダウンはしていませんでした。しかしながら、ping応答ができない程、不要なパケット通信が生じてしまいました。
5.まとめ
今回の事例は、原因となったServer-Bが発見しにくかったことです。当初は、帯域が利用されないのにも関わらず、Routerの電源off/on を行うと一時的にサービスが回復するため、Router、もしくは回線に関係することが原因と考えられていました。
パケットキャプチャーを行うことにより、当初考えていなかった、Serever-Bの存在が明確になり、その処理に問題があることを発見することができました。
