情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]

情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]
お客さまから、「Sales Forceのアプリの処理で非常に時間がかかる時がある」との問い合わせがあり、調査・原因を発見した例を示します。
【調査の流れ】
第一段階
EEC(End to End Checker :試験機)による現状把握
EECによる調査結果の分析
第二段階
原因の絞り込みのため詳細ログ入手プログラムの実行
【お客さまのシステム構成(概略)】
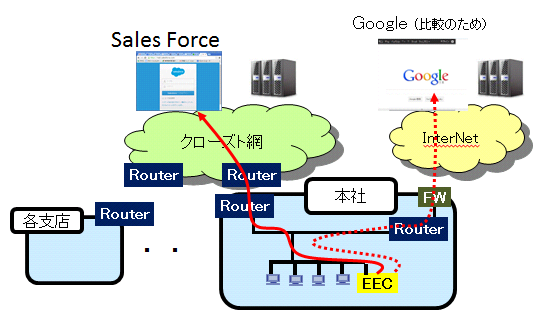
2.EECによる調査結果の分析
EEC(試験装置)より、
(1)ping試験 Sales Force サーバ
(2)80ポート試験 Sales Force サーバ、Googleサーバ
(3)wget試験 Sales Force サーバ、Googleサーバ
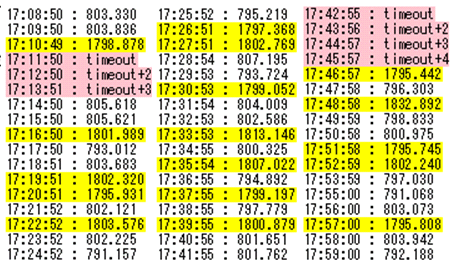
の各試験を実施
(1)ping試験結果 Sales Force サーバ 試験期間の月データ
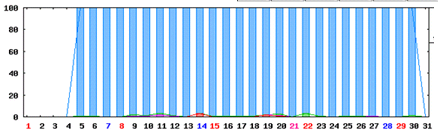
凡例 普通:青色、少し遅い:緑色、遅い:紫色、timeout:赤色
⇒ 特に問題なし
(2)80ポート試験結果 Sales Force サーバ 試験期間の月データ
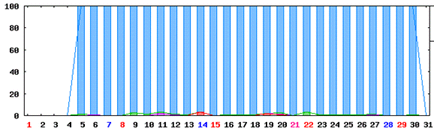
凡例 普通:青色、少し遅い:緑色、遅い:紫色、timeout:赤色
⇒ 特に問題なし
(3-1)wget試験 Sales Force サーバ 試験期間の月データ
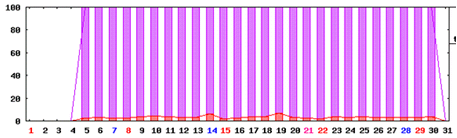
凡例 普通:青色、少し遅い:緑色、遅い:紫色、timeout:赤色
⇒ 問題あり。毎日タイムアウトが発生
(3-2)wget試験 Sales Force サーバ 試験期間のある日のデータ
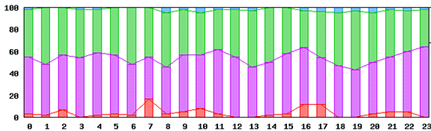
凡例 普通:青色、少し遅い:緑色、遅い:紫色、timeout:赤色
17時台の状況
タイムアウトが発生し、かなりのレスポンスの劣化があったと考えられます。
第一段階の試験では、タイムアウトのMaxを3秒としました。
(3-3)wget試験 Google サーバ 試験期間の月データ
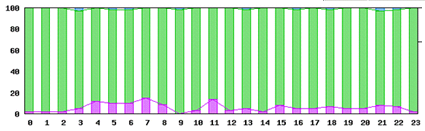
凡例 普通:青色、少し遅い:緑色、遅い:紫色、timeout:赤色
⇒ 特に問題なし
Googleサーバへのアクセスが特に問題なしであるため、Sales Force関連で何らかのレスポンス劣化の要因があると考えらます。
3.原因の絞り込みのため詳細ログ入手プログラムの実行
Sales Forceへのログインの推移の詳細ログを取ること(Rapid プログラミングによる)により、以下の状態遷移があることが分かりました。
冗長度構成となっており、アクセスの度に機器が選択されているのが分かります。

【待合せがない場合の詳細ログ(速い処理の場合)】
2015-04-03 11:22:31-- http://10.1.15.253/
10.1.15.253:80 に接続しています... 接続しまし
た。
HTTP による接続要求を送信しました、応答を待っています... 302 Found
場所: https://na6.salesforce.com/ [続く]
スパイダーモードが有効です。リモートファイルが存在してるか確認します。
2015-04-03 11:22:31-- https://na6.salesforce.com/
na6.salesforce.com をDNSに問いあわせています... 10.1.15.180, 10.1.15.190, 10.1.15.189
na6.salesforce.com|10.1.15.180|:443 に接続しています... 接続しました。
HTTP による接続要求を送信しました、応答を待っています... 200 OK
長さ: 特定できません [text/html]
リモートファイルが存在し、さらなるリンクもあり得ますが、再帰が禁止されています -- 取得しません。
処理時刻(前) = 2015-04-03 11:22:30.943563699
処理時刻(後) = 2015-04-03 11:22:31.943880069
処理時間 = 1.000 秒
【待合せがある場合の詳細ログ(遅い処理の場合)】
2015-04-03 11:24:28-- http://10.1.15.253/
10.1.15.253:80 に接続しています... 接続しました。
HTTP による接続要求を送信しました、応答を待っています... 302 Found
場所: https://na1.salesforce.com/ [続く]
スパイダーモードが有効です。リモートファイルが存在してるか確認します。
2015-04-03 11:24:28-- https://na1.salesforce.com/
na1.salesforce.com をDNSに問いあわせています... 10.1.15.213, 10.1.15.214
na1.salesforce.com|10.1.15.213|:443 に接続しています... 失敗しました: 接続がタイムアウトしました.
na1.salesforce.com|10.1.15.214|:443 に接続しています... 接続しました。
HTTP による接続要求を送信しました、応答を待っています... 200 OK
長さ: 特定できません [text/html]
リモートファイルが存在し、さらなるリンクもあり得ますが、再帰が禁止されています -- 取得しません。
処理時刻(前) = 2015-04-03 11:24:28.772465349
処理時刻(後) = 2015-04-03 11:25:32.571695763
処理時間 = 63.799 秒 ← ★ 63秒程、処理にかかっています。
4.原因について
今回の事例では、冗長化機器の中に正しく動作しない機器があることが判明しました。
この機器を冗長化リストから外すことによりレスポンス劣化を解消することができました。
<補足>
今回の例では、ping監視、ポート監視では発見できず、実際の動作も、60秒待てば処理が進むため、ネットワークや個別のPCが原因となる可能性もあり、原因の発見に時間を要しました。
できるだけアプリに近いレイヤで、レスポンスにばらつきがないかどうか、通常のテストでokの処理の場合もレスポンスを意識する必要があることが分かりました。
5.【参考】 保守・運用サービスに必要なこと(5点)との関係
今回の原因の発見については、 「保守・運用サービスに必要なこと」の5つのポイントの内、3項目の特徴を活用しました。また、1項目は、半分ぐらいの活用でしたので、今回の課題解決については、3.5の特徴を活用したと言えます。
●(1) アプリケーションレイヤーに近いレベルからの試験
(縦 方向の End to End 試験)
死活監視では分からない状況をよりアプリに近い試験を行うことにより、環境の微妙な違いを明確化します。
▲(2) クライアントからサーバまでの通し試験
(横 方向の End to End 試験)
利用する端末からサーバ(専用サーバ、クラウド)までには、スイッチ、ルータ、ネットワーク、ロードバランサ、Poxy、FW(フィヤーウォール)と色々な機器を通ります。その通しの試験を行うことが重要です。MIB情報が出せないような、MC(メディアコンバータ)等の不良も発見できます。
(3) 全機器の監視 (規模の軸)
できるだけ多く(できれば全ノード)の機器の試験を行うことが重要です。
●(4) 常時監視 (時間の軸)
悪い時にだけ試験を行うのではなく、常にITインフラの状況を把握しておく必要があります。 問題がない時の状況を把握し、少しでも状況が悪くなった場合に分かる仕組みが必要です。
●(5) カスタマイズ試験
今回は、「処理のシーケンスのログを全て出力し、処理時間の開始時刻と終了時刻をログに追加する」カスタマイズ試験を実施することにより、正常処理と異常処理の比較を容易に発見することができました。
6.まとめ
本ページで示した通り、「保守・運用サービスに必要なこと(5つのポイント)」によりトラブルの原因究明ができました。
ITサービスの安定運用は、トラブルが発生してから対処するのではなく、常に品質が上がるサイクルを連続する必要があります。
保守・運用サービスに必要なこと(5つのポイント)のページへ
