情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]

情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]
エンドユーザの申告前にトラブルを発見
ICTインフラの故障は、交通機関が止まったり、物流が止まる等、会社活動への影響は、これまで以上に大きくなっております。
できるだけ、故障の兆候を事前に発見し、未然に問題を解決することが重要ですが、
最低、一度遭遇した不具合は、
次からは、エンドユーザ(お客さま)の申告前に発見する。
ことが求められています。
【実現方法】
1.トラブルが生じた時は、技術者が故障個所の切り分け、試験を行います。その場合、いくつもの機器にログインし、状況を把握、試験を行うことにより、不具合の確認を行います。
2.”1.”で、技術者が行った作業内容(シナリオ)をプログラミング化し、そのシナリオを元に定期的に試験を行います。
(カスタマイズ試験)
【事例】
pingによる死活試験では、良好であったが、ネットワークのルーティングテーブルが更新されておらず、サービスが利用できなかった場合。
カスタマイズ試験
EEC(End to End Checker)より、定期的に機器を巡回し、ルーティング情報を集め、マスタデータと比較することにより、不具合を発見します。
どんなNMSを用いても、お客さま環境により、発見できないケースがあります。その場合、少し手を入れたツール(小道具)が有効です。
この小道具が、カスタマイズ試験です。
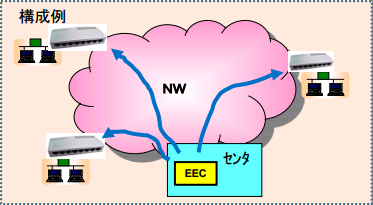
【類似例】
FW、ロードバランサ、その他サーバの特殊なログを暫定的に60分毎に入手したい場合があります。
この場合もカスタマイズ試験にて実現することができます。
2.カスタマイズ試験の構成3要素
「保守・運用サービスに必要なこと」の5つ目のポイントが、
⑤ カスタマイズ試験 です。
参考:「保守・運用サービスに必要なこと」の5つ目のポイント
① 上位から(縦方向のend-to-end軸)の試験
② クライアントからサーバまで(横方向のend-to-end軸)の試験
③ 全装置(規模軸)の試験
④ 常時監視(時間軸)
⑤ カスタマイズ試験
「保守・運用サービスに必要なこと」 のページもご参照下さい。
カスタマイズ試験の3つ要素について、メール遅延見える化システムの例を元に説明します。
3つの要素を次に示します。
(1)試験実行プログラム
技術者が、潜在故障の探索のために行った手順をシナリオ化し、試験を行い、結果を蓄積します。
通常の潜在故障は、1回の試験では発見が困難ですので、連続してこの試験を行います。
(2)表示のためのプログラム
”(1)”で行ったデータを、表、グラフ化して表示します。
ここで重要なことは、”違い”を発見することです。
良い時と悪い時の違いが発見できれば、原因究明に大きく近づきます。
1回の試験で分らなかった現象を、過去のデータを見ることにより原因の発見に繋がります。
(3)トラッププログラム
”(2)”で、違いが発見できた場合、違いの生じた時点で、アクションを取ることが可能です。
ある条件(閾値)を設定し、”(1)”で蓄積したデータの状況がその条件となった場合にアラームとします。アラームはメール等で保守者に伝えます。
以下、3つについて、メール遅延見える化システムを例に取り、詳細に説明します。
3.(1)試験実行プログラム
(1)試験実行プログラム
メール遅延見える化システムでは、被試験メールサーバに実際にメールを送り、そのメールが転送されてくる時間を測定しています。

・メールを送信する処理
・メールが返送されてきた場合に自動で起動する処理
上記2つの処理を行い、次のようなデータを連続して蓄積します。
送信時刻 着信時刻 Total処理時間(秒)
00:01:01.480 00:01:09.575 8.095
00:06:01.631 00:06:07.061 5.430
00:11:01.379 00:11:06.316 4.937
00:16:01.151 00:16:11.639 10.488
00:21:01.354 00:21:07.023 5.669
00:26:01.293 00:26:07.048 5.755
00:31:01.298 00:31:06.741 5.443
00:36:01.873 00:36:07.308 5.435
00:41:01.197 00:41:06.017 4.820
00:46:01.971 00:46:07.660 5.689
00:51:01.926 00:51:07.658 5.732
00:56:01.873 00:56:06.801 4.928
01:01:01.060 01:01:06.514 5.454
01:06:01.400 01:06:07.179 5.779
01:11:01.350 01:11:06.487 5.137
01:16:01.443 01:16:07.157 5.714
4.(2)表示のためのプログラム
”(1)”の出力だけを見ても良いのかどうか分かりません。
そこで、閾値の変化、時間毎の変化、他機器との比較を行います。
メール遅延見える化システムの例を示します。
次の例は、メールの遅延を60秒とした場合と900秒とした場合の比較のグラフです。
900秒では分からなかった状況が、60秒にすると鮮明になります。
例1:~6秒:青、6秒~60秒:緑、60秒以上:紫
閾値60秒以上
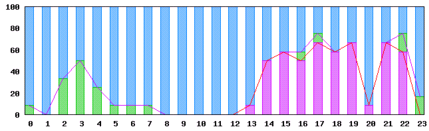
例2:~6秒:青、6秒~900秒:緑、900秒以上:紫
閾値900秒
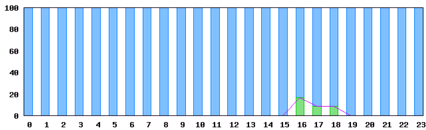
このように、閾値をダイナミックに変更して、過去のデータを分析することにより、”違い”を見つけることができます。
違いが発見できれば、どうしてこの違いが生じたかを追求していくことにより、原因に近づくことが可能です。
次に示すのは、ある被試験メールサーバのある月、次の月のデータです。
微妙な変化ですが、前月と変化があったことが分かります。
例3:ある月のデータ
メールある月のデータ
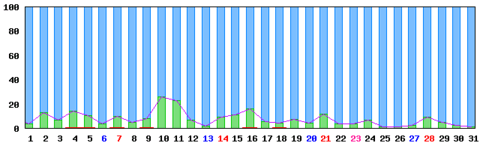
例4:次の月のデータ
メール次の月のデータ
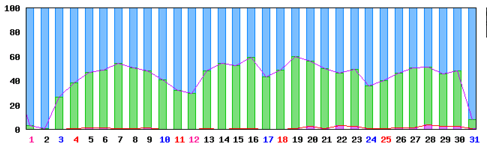
次に示すのは、ある日の被試験メールサーバを比較したグラフです。3番目の機器だけ遅延が発生しているのが分ります。
例5:被試験メールサーバの比較
被試験メールサーバの比較
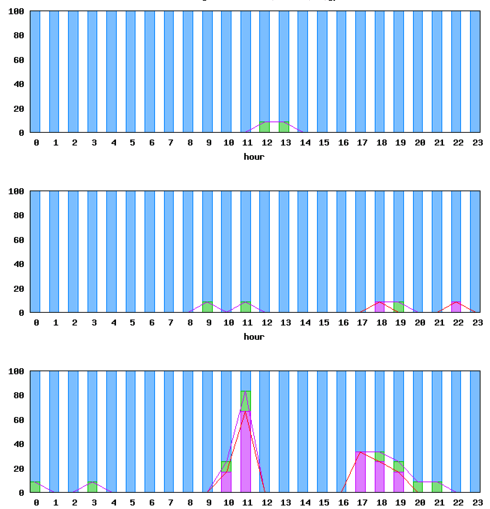
5.(3)トラッププログラム
"(2)"で、違いが発見できた場合、その違いに達した時に保守者に知らせる仕組みが必要です。
この機能により、エンドユーザの申告前に、ICTインフラの不具合を発見できるようになります。
以下で示す例は、メール遅延見える化システムのデモ環境の実際のデータです。メール遅延の閾値を60秒とシビアにしています。
例6:遅延が発生した時のメールの例
Now time is = 2015-11-06 04:36:21
Delay: 04:35 -> 1 minits AND Alart Mail
Aドメイン名
例7:遅延が回復した時のメールの例
Now time is = 2015-11-06 04:41:21
Mail Received as below:
sent at 15-11-06 04:35 mail is Received
Aドメイン名
例8:全ログの例
2015 年 11 月 06 日 (金) の 全ログです。
発見時刻: 種別, 送信時刻, ドメイン名 コメント
04:36:21: Alart, 04:35 mail, Aドメイン , 1 minits delay
04:37:29: Alart, 04:36 mail, Bドメイン , 1 minits delay
04:41:21: Sent , 04:35 mail, Aドメイン (etc) is Received
04:43:30: Sent , 04:36 mail, Bドメイン (etc) is Received
6.まとめ
時々使えない、冗長機器の中の一台が時々調子が悪くなる、等の潜在故障は、なかなか発見できません。
本ページでは、潜在故障を発見するため「保守・運用サービスに必要なこと」の5番目のカスタマイズ試験について説明しました。
「保守・運用サービスに必要なこと」の5つのポイント
① 上位から(縦方向のend-to-end軸)の試験
② クライアントからサーバまで(横方向のend-to-end軸)の試験
③ 全装置(規模軸)の試験
④ 常時監視(時間軸)
⑤ カスタマイズ試験
①~④では、発見できない場合も、⑤を実行することにより、
・エンドユーザの申告前に発見
・潜在故障の発見に貢献
が可能となります。
7.更なる発展:カスタマイズ試験結果からパケットキャプチャの自動起動
不具合の原因の発見には、パケットキャプチャが有効です。
本ページで説明した、カスタマイズ試験において疑わしい場合にパケットキャプチャを自動で起動すると言う連携が可能です。
パケットキャプチャーのページをご覧ください。
8.更なる発展:ログ解析
カスタマイズ試験を拡張することにより、ログ解析にも利用できます。
次は、ネットワーク遅延のページの、「8.パケットキャプチャによる解析」で示したものと同じ内容です。
関西クラウドセンタのWWWサーバ、北海道クラウドセンタのWWWサーバにおける、 wget [-spider オプション]の動作のパケットキャプチャを行いました。
キャプチャの場所は、EECのNICで行っています。 次の図は、各サイトへのアクセス状況の時間経過を示しています。
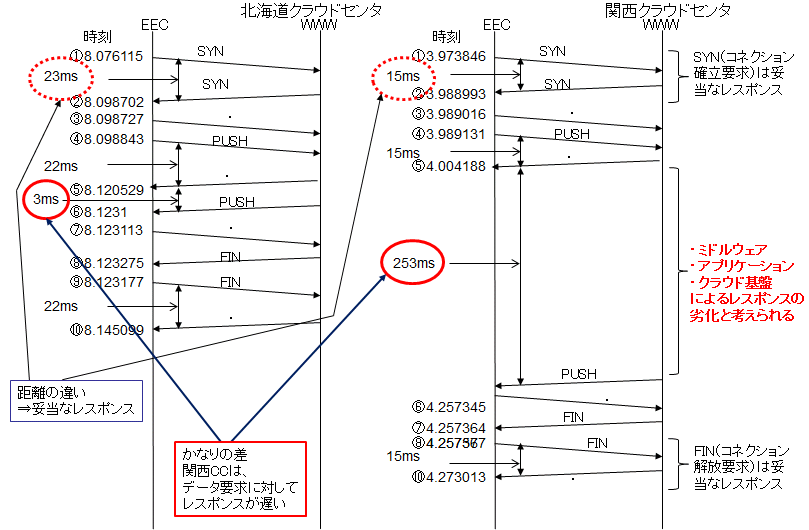
ネットワークの遅延:パケットキャプチャ
次に示すのは、httpsのクライアントで利用した55735 ポートの処理を示します。処理に時間がかっかた所を赤字としております。
このように、カスタマイズ試験を拡張して、特定のログの抽出が可能です。この抽出により、分かり難い問題解決に貢献することが可能です。

9.カスタマイズ試験例【その2:実運用中】
実際に運用している例について説明します。
ITサービスを提供していると、どうしても原因が分らない事象に遭遇します。
<サーバ機器であれば>
(1)なぜか、プロセスが止まってしまう。
(2)突然リブートする事象が発生し、次回、いつリブートが起きるか分らず、対応に苦慮する。
(3)ゾンビプロセスが発生し、CPUの負荷が異常に高くなることが発生する。
のような現象です。
原因が不明のままでも、サービスの停止は許されませんので、上記のような現象の発生が分れば、
(1)プロセスの再起動
(2)リブートが発生した場合、リブート後に必要な処理の実行
(3)ゾンビプロセスの強制終了
で、暫定対処が可能です。
カスタマイズ試験は、お客さま環境に応じて試験を行い、原因が分らない不具合の事象の発見を行い、暫定対処が必要なことをお客さまにお知らせします。
カスタマイズ試験は、サービス停止期間を短くするばかりでなく、オペレータの精神的負担の低減、作業の効率化に繋がります。
今回のシステム構成
今回は、「あるサーバが、1カ月ぐらいするとなぜかリブートになる事象が続いた」ことをトリガに構築しました。
リブート後には、業務で必要なプログラムを起動する必要があります。リブート後に自動でプログラムを起動させることもできますが、他システムとの整合性のため、チェックが必要なため、リブートがあった事実を保守者に知らせる仕組みを検討しました。
リブートの情報以外にも、ITサービスの安定した運用に必要な情報を入手する仕組みを追加しました。
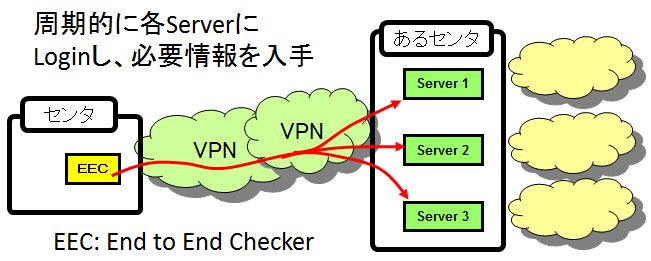
カスタマイズ試験の3要素の具体例
カスタマイズ試験の構成3要素
(1)試験実行プログラム
⇒ 統計情報の作成
(2)表示のためのプログラム
(3)トラッププログラム
になります。
各項目について、今回の例を説明します。
(1)試験実行プログラム
30分毎に、各サーバにログインし、次の項目を調べ、ファイルに蓄積します。
ア)今フォーカスしている業務のプロセス一覧
イ)サーバの連続起動時間
ウ)サーバの負荷(1分、5分、15分)
試験実行プログラムは、単に試験を行い、結果をファイルに蓄積していくシンプルな動作です。
この情報が、統計情報となります。
<統計情報の例>
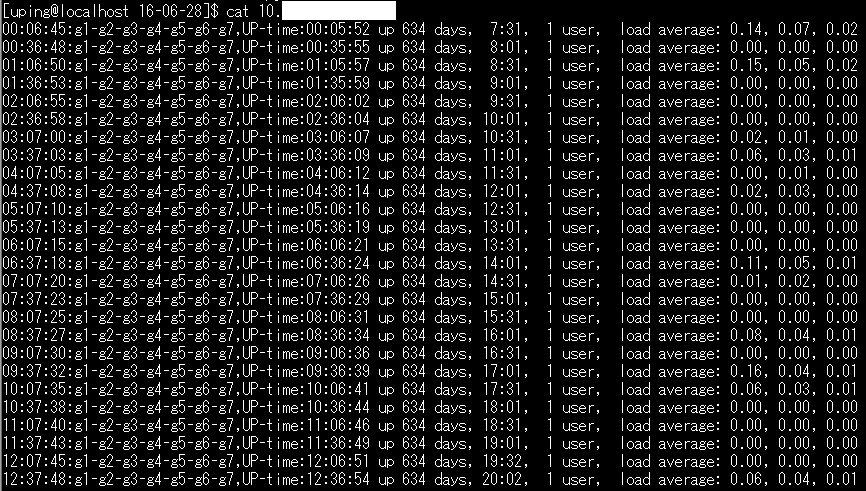
(2)表示のためのプログラム
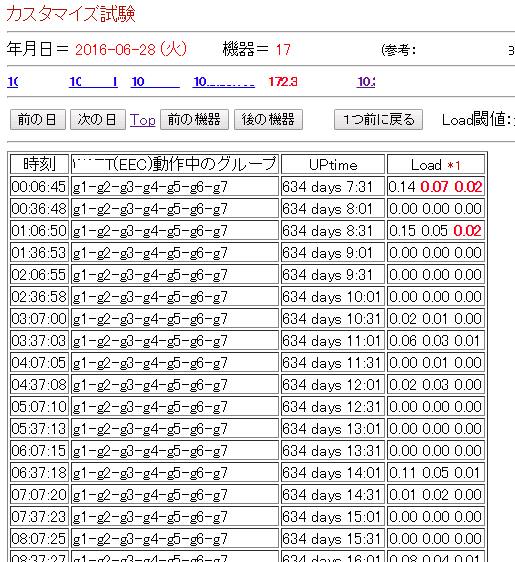
次に示す例は、実際の表示例です。
1番左が、試験時刻、2番目が該当プロセス一覧、3番目が起動時間、4番目が負荷になります。
<実際の表示例>
(3)トラッププログラム
試験実行プログラムによって作成した、統計情報で各機器のサーバの不具合を発見するために、トラッププログラムを実行します。
今回のトラップ条件を次に示します。
trap_0 : 1 時間以内に最終logの書き込みが無い場合
trap_1 : 起動プロセスに差がある場合
trap_2 : UPtime が減少している場合
trap_3 : load 15分が、2.0 以上の場合
上記のトラップ条件に合致した場合は、アラートメールを保守者に送信します。
トラッププログラムの起動・停止画面を次に示します。
トラップ条件は、画面上から変更できるため、閾値を変更し、シビアな環境の試験も可能となります。
<トラッププログラムの起動・停止画面例>

まとめ
カスタマイズ試験の実際の例を紹介しました。
今回の事例は、サーバへのカスタマイズ試験でしたが、NW機器、NW機器とサーバの両方の状態の試験、等々、多くの機器の確認業務として利用できます。
ITインフラは、お客さま毎に微妙に環境が違うため、一律的な試験では満足できないことがあります。
今回紹介したカスタマイズ試験は、
(1)試験実行プログラム
⇒ 統計情報の作成
(2)表示のためのプログラム
(3)トラッププログラム
の3つの要素の非常にシンプルな構成です。
日々、変更となる管理対象に対して、柔軟に対応でき、情報システム部門の方の無駄な稼働を減らすことが可能です。
トータル監視の5番目の要素の「カスタマイズ試験」により、ITインフラサービスの安定運用、想定外のトラブルの減少に貢献することが可能です。
