情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]

情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]
トラブルの原因を究明するためには、Router、Switch等にある情報を入手し、細かなデータの分析が有効です。
例えば、
・短時間の突発的なトラフィック
・ある時間帯のオーバーフロー値 等のデータです。
今回、簡易ですが、各機器(Router、Switch等)に定期的にloginし、情報を入手、そのデータの見える化を実現しました。
今回の例は、(1) CPU、メモリの使用率、 (2) トラフィック の見える化ですが、
今、office365で課題となっている、セッションの見える化も同様の方法で実現が可能です。
各種トラブル時の原因究明に貴重なデータとして提供することが可能となりました。
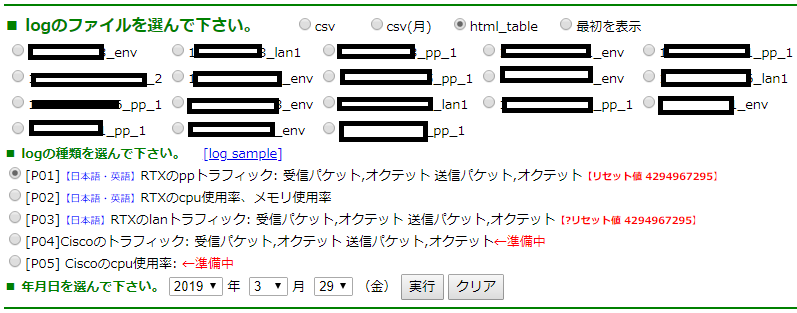
1.「機器へのloginで入手した情報の見える化」機能のTop画面
本機能のTop画面を次に示します。
定期的(1分毎等)に機器にloginして、情報を入手します。その検索結果をlogファイルに残します。
・IPアドレス.env : cpu使用率
・IPアドレス.lan1 : lan側トラフィック
・IPアドレス.pp_1 : wan側トラフィック を示します。
画面にあります、
■ logのファイルを選んで下さい。
■ logの種類を選んで下さい。
■ 年月日を選んで下さい
の3項目を選ぶことにより、cpu使用率、トラフィック、その他の表示が可能となります。
以下、それぞれの項目について詳細に説明を行います。
2.検索事例:CPU使用率
次の例は、ある機器の2月12日のCPU使用率のデータです。
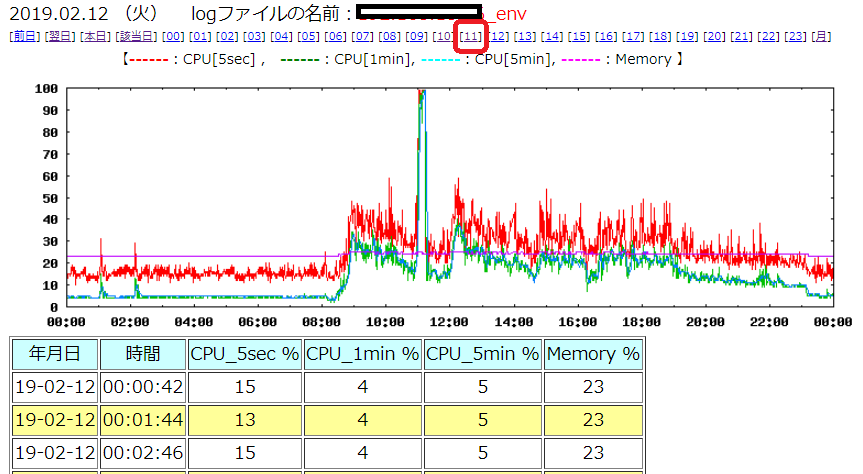
11時ごろ、非常に高くなっていますので、図の上の方の [11] (11時)をクリックします。
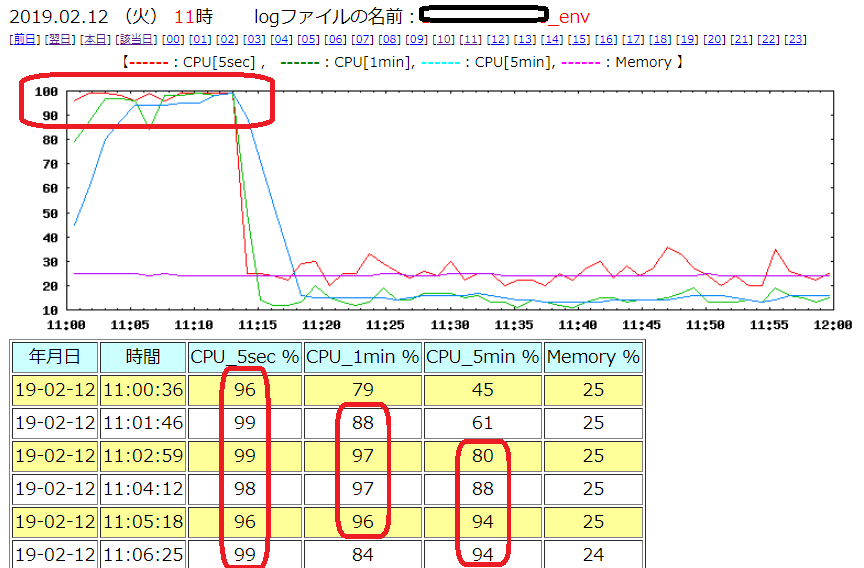
11:00~11:14ごろまで、CPU使用率が非常に高くなっていることが分かります。
参考にEEC(End to End Checker)で、この機器にping試験を行ったグラフを以下に示します。
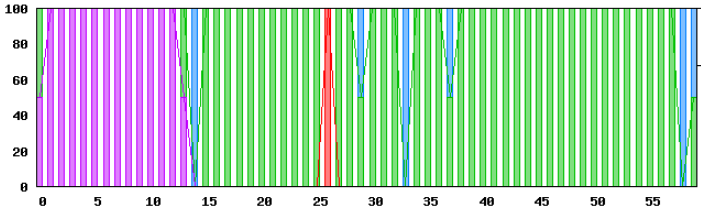
この例では、ping試験の遅延状況を見て、どこかに問題があるかどうかが分かることを示しています。
このように、EECによる試験で遅延が発見できますので、
EECで要注意となった機器について、今回の様な方法で詳細調査を行うことが可能です。
トラブルの原因究明、問題の明確化に貢献できます。
ポイントとしては、まず、EECにて、全体を俯瞰すような試験を実施することです。
EECは、非常に軽い負荷になりますので、なるべく多くの機器を試験することが可能で、鳥瞰図的に悪い部分を抽出します。
3.検索事例:回線使用率(トラフィック)
次の例は、ある機器の2月7日のWAN側のトラフィックのデータです。
各機器には、〇〇Mbpsのような、トラフィックの数値はありません。
次の例は、ヤマハのルータの show status pp 1 コマンドの例です。
---- from hete ----
show status pp 1
PP[01]:
説明: to_xxxxx
PPPoEセッションは接続されています
接続相手: xxx
通信時間: 35日12時間36分4秒
受信: 2120085285 パケット [2804921162 オクテット] 負荷: 0.0% ←★
送信: 2888449756 パケット [2627227197 オクテット] 負荷: 0.1% ←★
PPPオプション
LCP Local: Magic-Number MRU, Remote: CHAP Magic-Number MRU
IPCP Local: IP-Address, Remote:
PP IP Address Local: 192.xxx.x.xxx, Remote: Unnumbered
CCP: None
xxxxRouter
---- end ----
トラフィックを抽出するためには、上記の ★ 部分から計算して求める必要があります。
以下のグラフは、入手したlogより、トラフィックを計算して作成したものです。
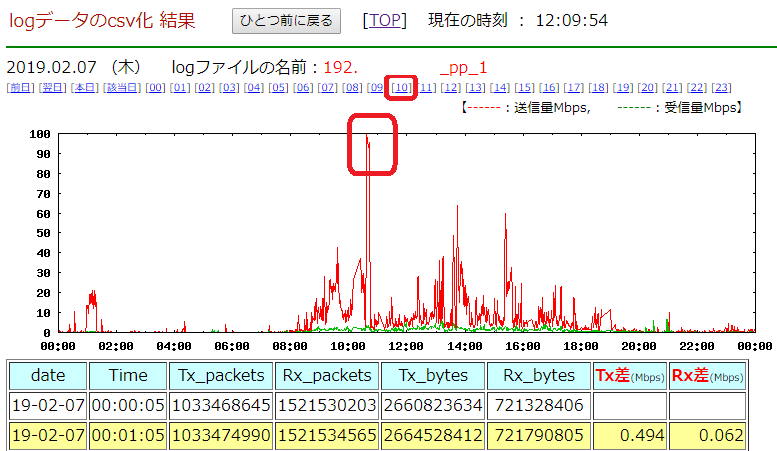
10時台に高くなっている所があります。上の [10] 10時をクリックすると、より詳細情報を表示します。
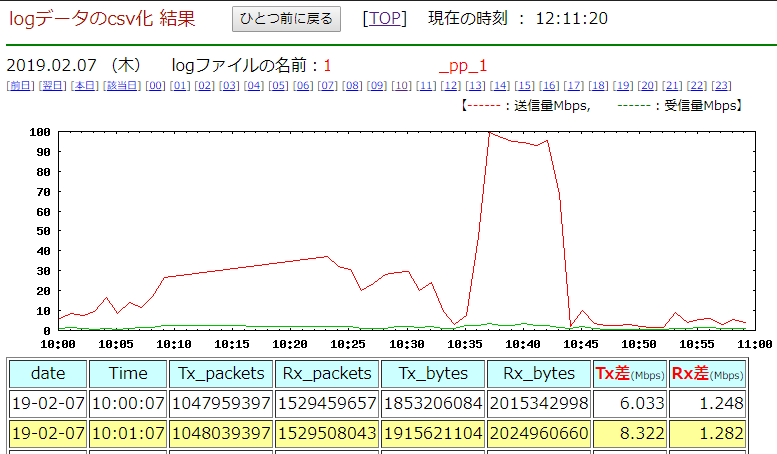
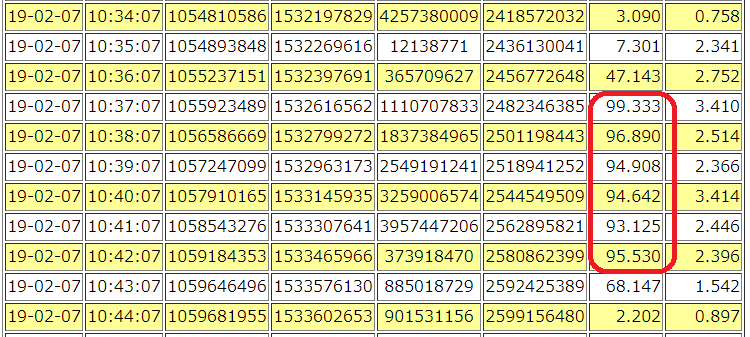
10:37~10:42ごろ、100Mbps 程度とトラフィックが高くなっています。
この日が特別だったのか、頻繁に起こっているかを見るためには月データを検索します。
次のグラフは、月データのグラフです。
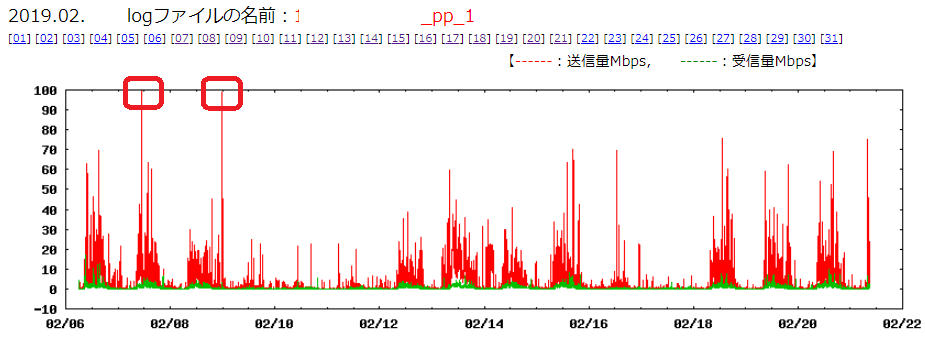
今回の例では、2月の全データは取得できていませんが、2月7日以外にも、8日に高いトラフィックを記録したことが分かります。
このように、常時データを取得し、マクロ表示を行うことにより全時間帯でのトラフィック状況の把握が可能となります。
まとめ
今回の例は、(1) CPU、メモリの使用率、 (2) トラフィック の見える化ですが、
各機器には、色々な情報が残されており、トラブルの原因分析には貴重なデータとなります。
まず、EEC(End to End Checker)にて、基本的な試験を行い、要注意機器については、今回の様に機器にloginしてデータを取り続けます。
データを取り続けて、マクロ的に分析することが重要です。長いスパンでデータを分析をするとトラブルの兆候となる数値が現れることがあります。
変化には必ず要因がありますので、エンドユーザ様の影響になる前に問題を回避するためにも、
本ページで紹介した、「機器へのloginで入手した情報の見える化」は重要なポイントとなります。
