情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]

情報システム部門の煩わしい業務を効率化
ITサービスの運用を変革します。[お問合せ]
クラウド時代になり、ITインフラ構成は複雑になりました。企業活動のITの利用は業績に大きく影響するようになり、ITサービスが問題なく利用できていることが増々重要になってきました。
しかしながら、現状では、昨日のITサービスがうまく動作していたのか、していないかのエビデンスがありません。
また、ITインフラの中に潜在故障がある場合には、一番肝心な時にサービスを利用できないと言うリスクがあります。
自動車にドライブレコーダーがあるように、ITサービスがうまく利用できているかどうかの記録が必要です。
ITサービスレコーダーは、ITサービスが問題なく動作していたかどうかの過去の記録を残します。
残された記録を元に、トラブルの兆候を発見し、トラブルを事前に回避できるように、「予防保全」に貢献します。
情報システム部門の業務を強力に支援し、
使えば使うほど品質が良くなる仕組みを提供し、ITサービスの運用業務を変革します。
ITサービスレコーダーのパンフレット(pdf)
EECの監視機器の登録推奨手順 と 品質が常に向上する施策(pdf)
ITインフラ可視化サービスのパンフレット(pdf)
ITインフラ可視化分析サービス概要ver3.1.pdf
ネットワークエビデンスサービス概要v2.2.pdf
2.ITサービスレコーダーを見るだけで、ITインフラサービス状況を把握
ITサービスレコーダーは、基本的なネットワーク監視、サーバ監視の機能を持ったEECを内蔵しています。
(EEC:End to End Checker )
EECを利用するだけで、ITインフラの相当な範囲の状態を見ることが可能です。
お客さまが、ITインフラサービスを維持するための監視装置を導入されているケースがありますが、そのアラーム情報をITサービスレコーダーに取りこむことにより、
「ITサービスレコーダーを見るだけで、ITインフラサービス状況を把握」することができます。
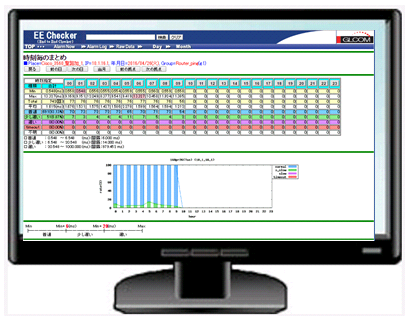
【画面イメージ】

3.カスタマイズ試験
ICTインフラの故障の会社活動への影響は、これまで以上に大きくなっております。
できるだけ、故障の兆候を事前に発見し、未然に問題を解決することが重要ですが、
最低、一度遭遇した不具合は、「次からは、エンドユーザ(お客さま)の申告前に発見する。」ことが求められています。
これを実現するのが、「カスタマイズ試験」です。
【実現方法】
1.トラブルが生じた時は、技術者が故障個所の切り分け、試験を行います。その場合、いくつもの機器にログインし、状況を把握、試験を行うことにより、不具合の確認を行います。
2.”1.”で、技術者が行った作業内容(シナリオ)をプログラミング化し、そのシナリオを元に定期的に試験を行います。(カスタマイズ試験)
このカスタマイズ試験を短期に作成し、タイムリーにお客さまに提供します。
詳細は、サービスの「カスタマイズ試験」の項目をご参照下さい。
4.アクションレポート
定期的に(通常3カ月に1回)アクションレポートを提出します。
お客さまのITサービスの利用の現状、トラブル状況、取るべきアクションを端的に提供します。
次に示しますのは、あるお客さまへのアクションレポートの抜粋です。
アクションレポートの例(抜粋)(pdf)
(1)課題のあるノードは、別グループにより特別監視を行います。
(2)問題がないグループでは、遅延にフォーカスして、レスポンス値の閾値をシビアにし、月に数回程度はアラーム記録が残るように設定します。
(3)潜在故障等原因が分かり難い場合は、カスタマイズ試験を行い各種トラップを設定し、原因究明を試みます。
5.遅延に関するお客さまの不満の限界値
次にEECの表示例を示します。
ネットワークに接続されたどのPCからも、WEBブラウザを利用してEECの情報を表示できます。
表示例1:ある日のデータで、拠点EECから、WEBサーバにWGET試験を行った例を示します。
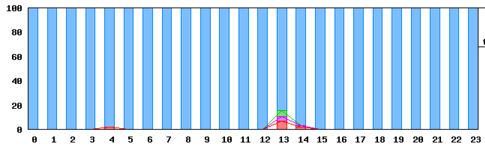
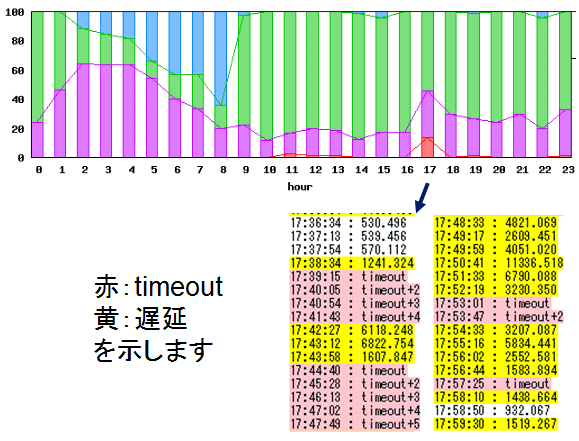
凡例 青:速い、緑:少し遅い、紫:遅い、赤:timeout
表示の見方は、例えば、1時間に100回試験をして、100回とも速ければ、全て青色になります。
仮に、50回が速く、50回が少し遅い場合は、半分が青色、半分が緑色となります。すなわち、速い、遅い、少し遅いのパーセント表示を行っています。
青、緑、紫の閾値は自由に変更できます。例えば、この日の13時台は、「使用に支障が出た」とエンドユーザから申告があれば、閾値を変えて13時台が、他の時間と違いが出るように閾値を変更します。
表示例2:上記と同じ日で、閾値をシビアにした場合の例を示します。
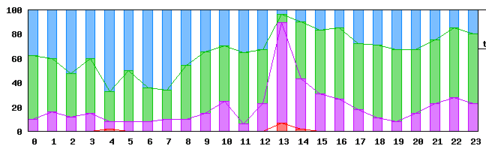
上記の例の13時台のような色分布の場合を、
エンドユーザがアプリケーションを使う場合の耐え難い遅延値として、
その閾値を「不満の限界値」とします。
この限界値を元に、同じような現象が生じるかどうかによって、ITサービスが問題なく利用できたか、利用できないかを判断します。
次のグラフは限界値を示したイメージ図です。
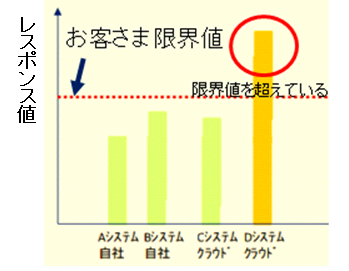
表示例2の13時のような場合には、限界値を超えたことになります。
このように、限界値を定義できましたので、その限界値を超えていなければ、ITサービスが問題なく利用できていたことが証明できます。
6.全機器をシンプルなワンインタフェースで表示
ネットワーク機器、サーバ、クラウド機器の全ての機器をシンプルなワンインタフェースで表示します。
該当機器、サーバについてのレスポンスタイムを時間軸ごとに棒グラフのパーセントで分かり易く表示します。
普通 :青色
少し遅い:緑色
遅い :紫色
timeout:赤色
と、単一インタフェースで、全てのITサービス機器を表します。
画面出力イメージ
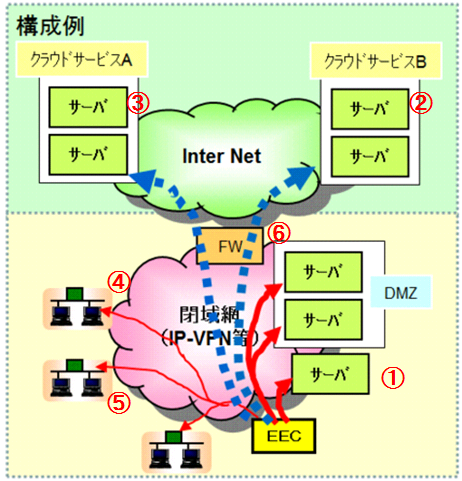
次に示すのは、ITサービスレコーダを設置した構成例です。
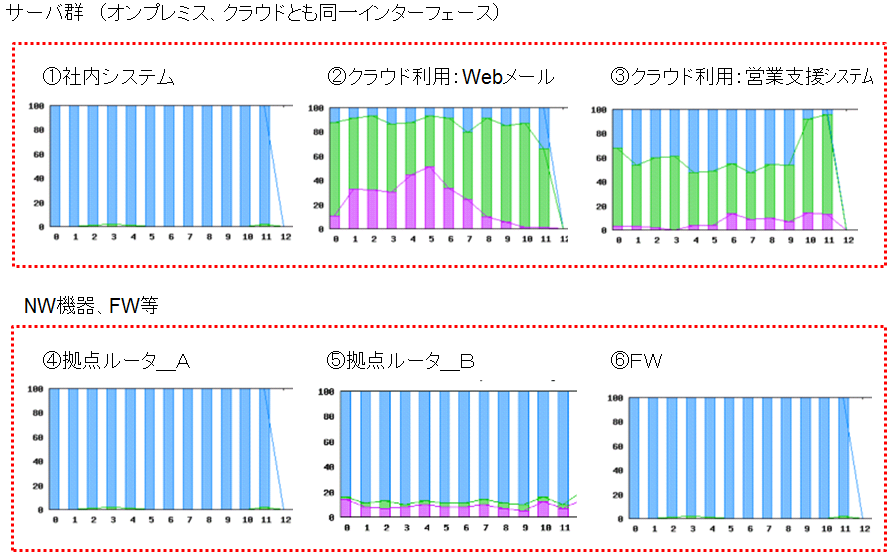
<サーバ群 (オンプレミス、クラウドとも同一インターフェース)>
①社内システム
②クラウド利用:Webメール
③クラウド利用:営業支援システム
<NW機器、FW等>
④拠点ルータ_A
⑤拠点ルータ_B
⑥FW
の機器を同じパターンで分かり易く表示します。
ITサービスレコーダーの統一した表示例
7.導入のメリット
情報システム部門の方に取って次の4つのメリットがあります。
(1) 常時監視
利用者からみた、ITインフラのサービス提供をリアルタイムで監視することができます。
通常の監視装置としても利用できます。
(2) エンドユーザからの問合せに明確に回答できます。
次の例では、「17時台に不具合だった」のが分ります。
これまでは、「調べてみます。」の回答でしたが、
これからは、不具合を事前に発見できますので、
「不具合を発見しておりますので、現在対応中です。暫くお待ちください。」
の回答が可能となります。
(3) 予防保全、機器の不具合の兆候の発見
統計情報(月毎故障のまとめ)により、
ITインフラの予防保全、機器の不具合の兆候を発見できます。
閾値を厳しくすることにより、常に、品質レベルの悪い機器、ノードを抽出することができ、
品質改善に繋がります。使えば使うほど品質が向上して行きます。
(4) ベンダ(クラウド利用を含む)、キャリアへの明確な指示ができます。
全ての機器、常時の監視記録があるため、ベンダ、キャリアにトラブルの状況を明確に伝えることができます。
エビデンスなしのベンダへ問合せでは、確りした調査を行って貰えないケースが多いですが、
エビデンスを付けて、問合せを行うことにより、問題解決が早まります。
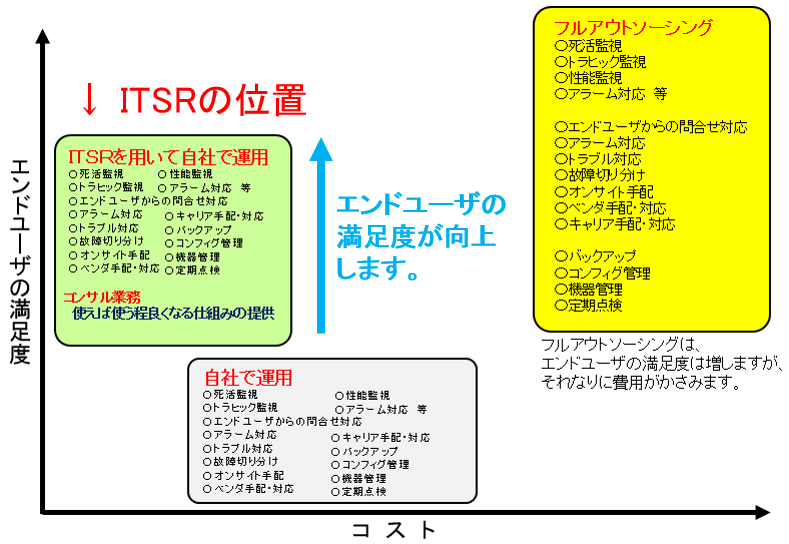
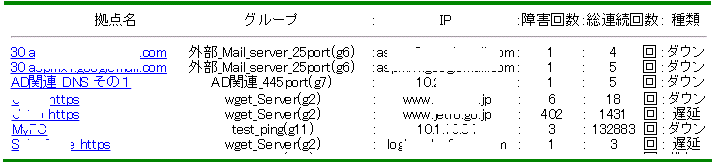
8.自社でのNMS運用とITSRを利用した場合の比較
各種NMS(ネットワークマネージメントシステム)がありますが、
自社で運用されている場合、次のような問題点はありませんか。
(1)NMSの豊富な機能を使いこなせない。
(2)機能を覚えるのに時間がかかる。
(3)毎月故障が起きるわけではないので、ツールを理解するための時間が無駄。
(4)導入したものの、殆ど触っていない。
(5)性能監視(CPU能率、プロセス監視等)を行っているが、少し複雑な実際のトラブルでは、有効
に機能していない。
(6)日々の業務に追われ、ある時大きなトラブルが発生し、慌てて改善の繰り返し。
自社でNMSを利用された場合とITサービスレコーダーを利用した場合の比較を次に示します。